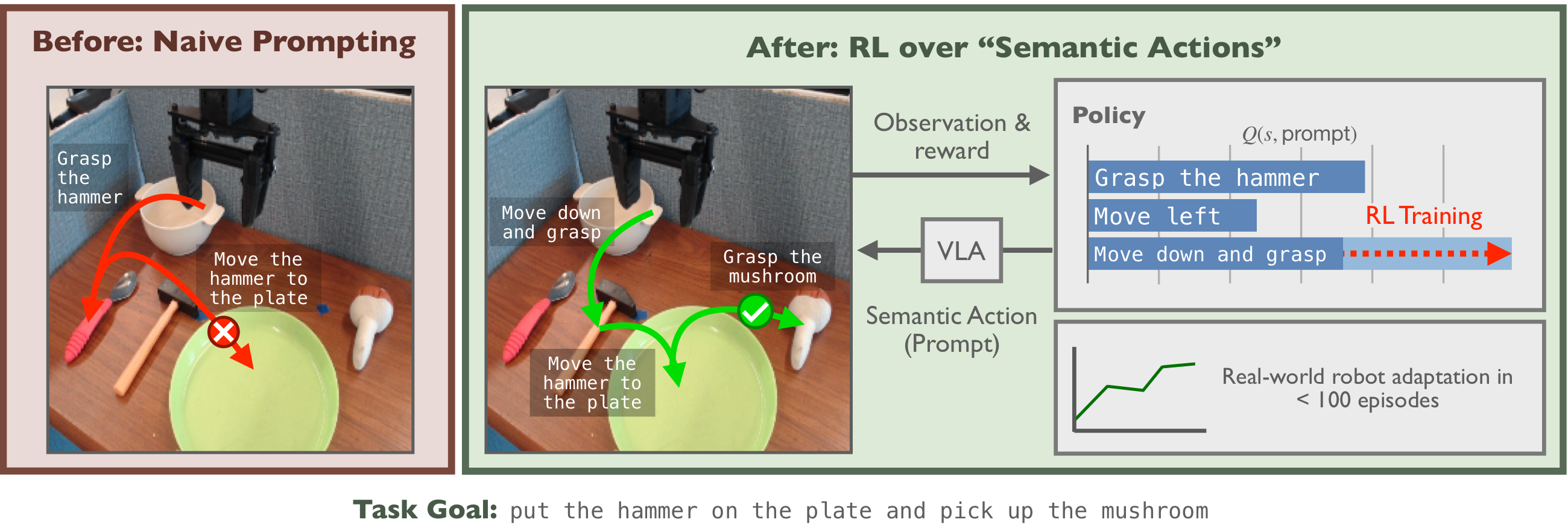
How can we adapt generalist policies at deployment time to go beyond their pre-training?
Vision-language-action (VLA) models learn broad skill repertoires from pretraining, giving us powerful priors over plausible robot behaviors. The standard strategy is to just prompt these models with new, desired task goals. However, as tasks scale in complexity and horizon, a successful policy must implicitly decompose goals into atomic, executable behaviors, and ground each behavior in a skill the robot can actually pull off in its current context. Often, directly prompting a VLA with a challenging goal fails.
Ask a VLA to move the hammer to the plate, then grasp the mushroom and its action distribution collapses into the wrong modes — it moves the mushroom to the plate and grabs the spoon instead.
A VLM can break the goal into sensible sub-instructions, but has no idea which commands actually work on this robot. Saying grasp the hammer makes the VLA grab a spoon; only move down and grasp succeeds. Plausible ≠ grounded.
The only way to know which prompts actually make progress is to try them on the robot and learn from the result. SARL runs RL over the prompt space, learning a grounded mapping between semantic actions and physical behaviors, achieving both decomposition and grounding.
SARL runs RL over a VLA's language prompts, lifting learning from robot actions to the semantic level.
Rather than viewing a VLA as a policy to be statically prompted, we view it as a semantically controllable action prior that can be dynamically guided throughout deployment. This motivates a simple but powerful transformation of the RL problem: instead of learning over the robot action space \(\mathcal{A}_{\mathrm{robot}}\) (joint positions, end-effector deltas, etc.), we learn over a semantic action space \(\mathcal{A}_{\mathrm{sem}}\) — the space of language commands — and deploy the VLA as a transformation between the two. We call the resulting induced problem a semantic MDP.
Concretely, at each step SARL picks a semantic action (a prompt) \(\ell\), the VLA turns it into robot actions, and the environment transitions and returns a reward. SARL learns a semantic Q-function \(Q_{\mathrm{sem}}(s, \ell)\) via temporal-difference backups that estimates how effective each prompt is at making task progress, and acts by sampling from the softmax over these Q-values. Finally, naively searching over all possible prompts is intractable, so SARL uses a VLM to propose a small set of candidate semantic actions from the current observation and task.

Task suite. We evaluate on four complex, long-horizon WidowX tasks (above), plus ten tasks on the simulated LIBERO-10 benchmark. These tasks are multi-step and require composing skills seen during pretraining (Bridge V2 for real, LIBERO-90 for sim) — the base policies achieve near-0% success on most of them, making them a clean test of deployment-time adaptation.
SARL improves the base VLA's success rate from near 0% under the task prompt up to ~80% after only 60–100 online episodes, in both the real world and simulation. It beats action-space RL methods (DSRL, Residual RL) that are fundamentally limited by the base policy's behavior under a single fixed prompt, and it beats an in-context-learning VLM baseline that proposes plausible commands but struggles to ground them in physical behavior.
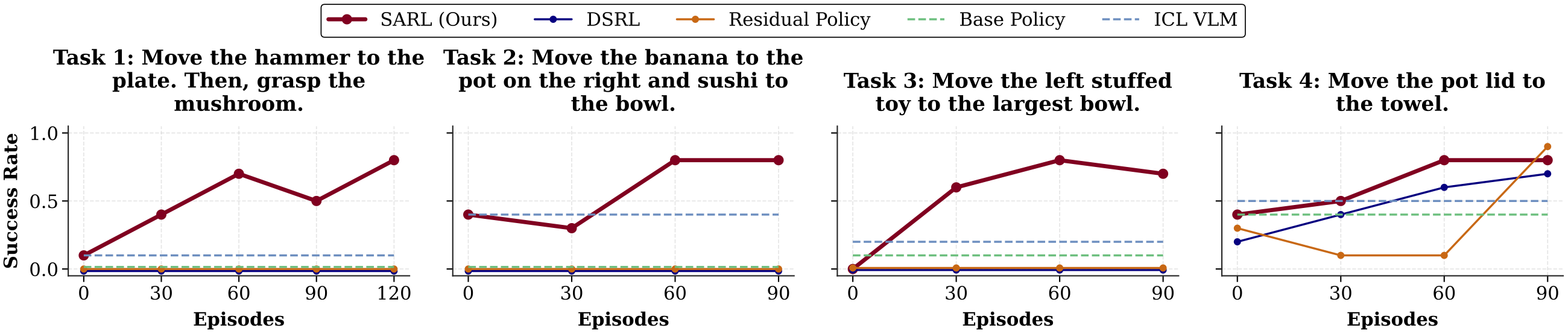
Real-world WidowX. Across all four long-horizon tasks, SARL achieves the best improvement of generalist-policy behavior in deployment. Each data point represents 10 evaluations.
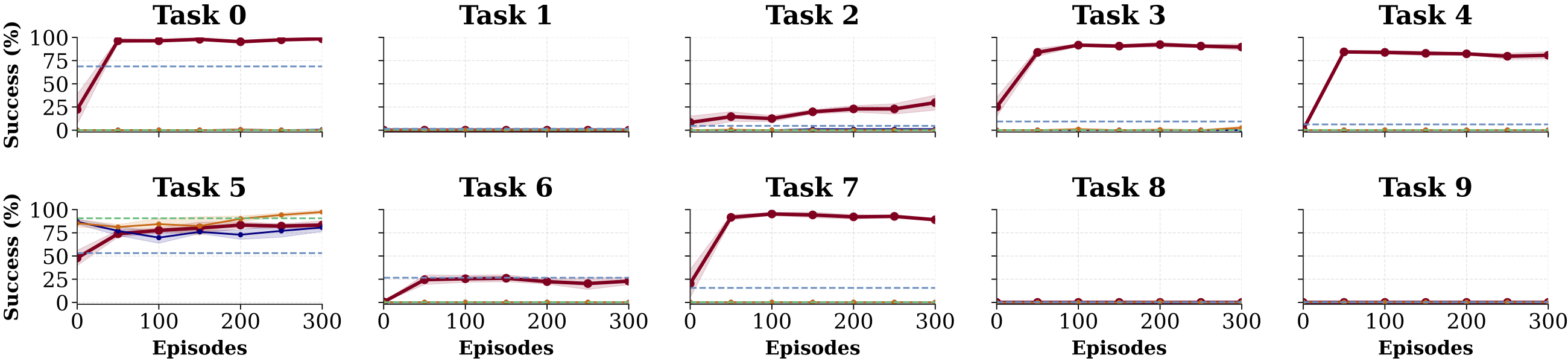
Simulated LIBERO-10. On long-horizon LIBERO-10 tasks, SARL outperforms DSRL, Residual RL, and the ICL VLM. It successfully adapts the policy on five tasks and matches performance on another that is already near-solved. Each point represents 64 evaluations with standard error over 3 seeds.
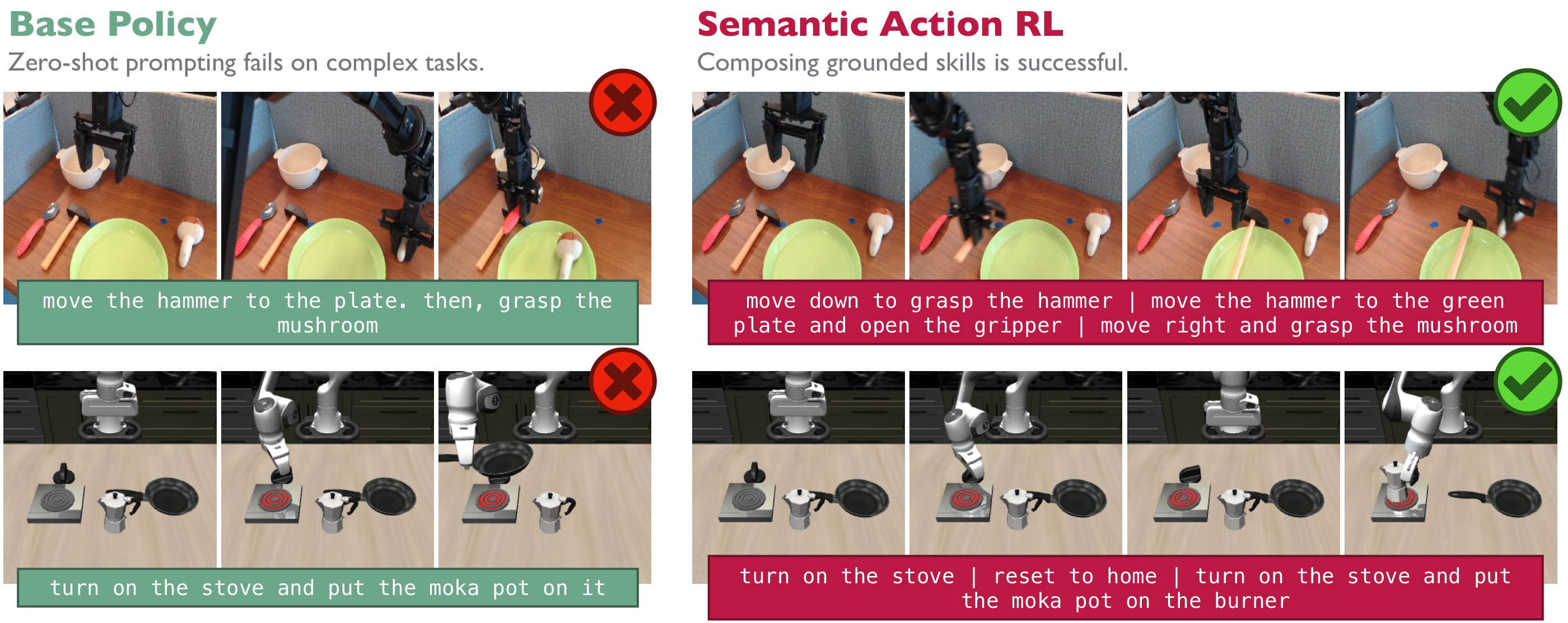
SARL vs. action-space RL. On complex, long-horizon tasks the base policy fails when zero-shot prompted — its action distribution collapses into entirely incorrect modes. Action-space methods can only filter or nudge around that distribution, so they only learn when the base policy is already close to succeeding. By editing the prompt, SARL reaches regions of the VLA's behavioral prior that are inaccessible to action-only steering, sequencing skills covered under pretraining to solve the task.
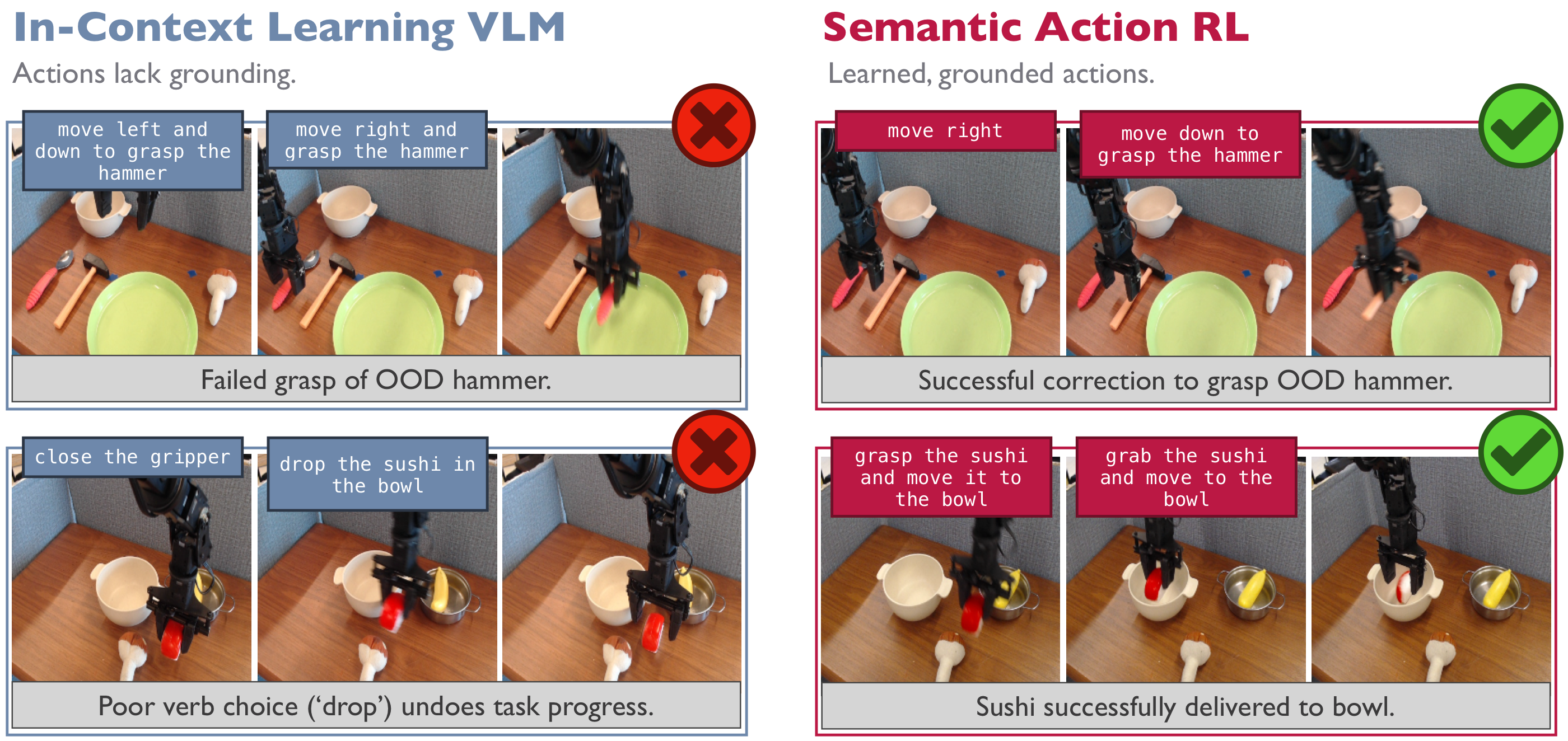
SARL vs. VLM prompting. An in-context-learning VLM picks commands that are semantically meaningful but lack grounding, leading to failures: it references an out-of-distribution “hammer” by name (making the VLA grab a spoon), or picks the wrong verb (drop), prematurely releasing the sushi. Through many episodes of experience, SARL learns the grounded behavior each command induces and selects the prompt that actually works.
Watch SARL learn each task online, sped up 30x.
@misc{bhatia2026sarl,
author = {Bhatia, Jagdeep Singh and Wagenmaker, Andrew and Chen, William and Levine, Sergey},
title = {Adapting Generalist Robot Policies with Semantic Reinforcement Learning},
year = {2026},
}